Document review is the most expensive component of eDiscovery. According to RAND Corporation research, review accounts for approximately 73% of total production costs, at roughly $14,000 per gigabyte of data processed. The EDRM 2024 Pricing Survey found that managed review rates have settled in the $0.50 to $1.00 per document range, but that covers only the review itself. Add vendor collection, processing, platform hosting, seed set coding at senior attorney rates, a separate privilege pass, response drafting, and QC sampling, and the full end-to-end cost of a discovery response scales quickly with document volume and case complexity.
Cost is only part of the problem. The consistency of human review has long been questioned. In a widely cited 2010 study, Roitblat, Kershaw, and Oot found that two independent teams of trained contract attorneys reviewing the same 1.6 million documents agreed on just 28% of relevance determinations (Jaccard index). Technology-Assisted Review improved on that baseline meaningfully. Grossman and Cormack demonstrated that computer-assisted classification outperforms manual review on recall, precision, and F1. But TAR introduced its own architectural constraints. It classifies documents as relevant or not relevant to the matter as a whole, not to individual requests. It requires a manually coded seed set to train the classifier. And it produces a confidence score without a natural language explanation of the reasoning behind it.
Lumios takes a fundamentally different approach. Rather than training a classifier on seed sets, the system uses large language models to semantically score every document against every individual discovery request, zero-shot, with natural language reasoning for each assessment. High-confidence decisions are auto-coded; uncertain documents are routed to human reviewers. Three layers of privilege protection ensure that every privilege determination is made by an attorney, not the AI. Statistical sampling validates the process to courtroom standards. The attorney remains the decision-maker at every stage. This post walks through how the system works, end to end.
The Five-Stage Workflow
The Lumios discovery workflow moves through five stages: Draft, Tagging, Review, Responses, and Completed. Each stage is designed so that the AI handles the high-volume, pattern-recognition work upfront, and the attorney focuses on the decisions that require legal judgment.
Stage 1: Upload & Extract
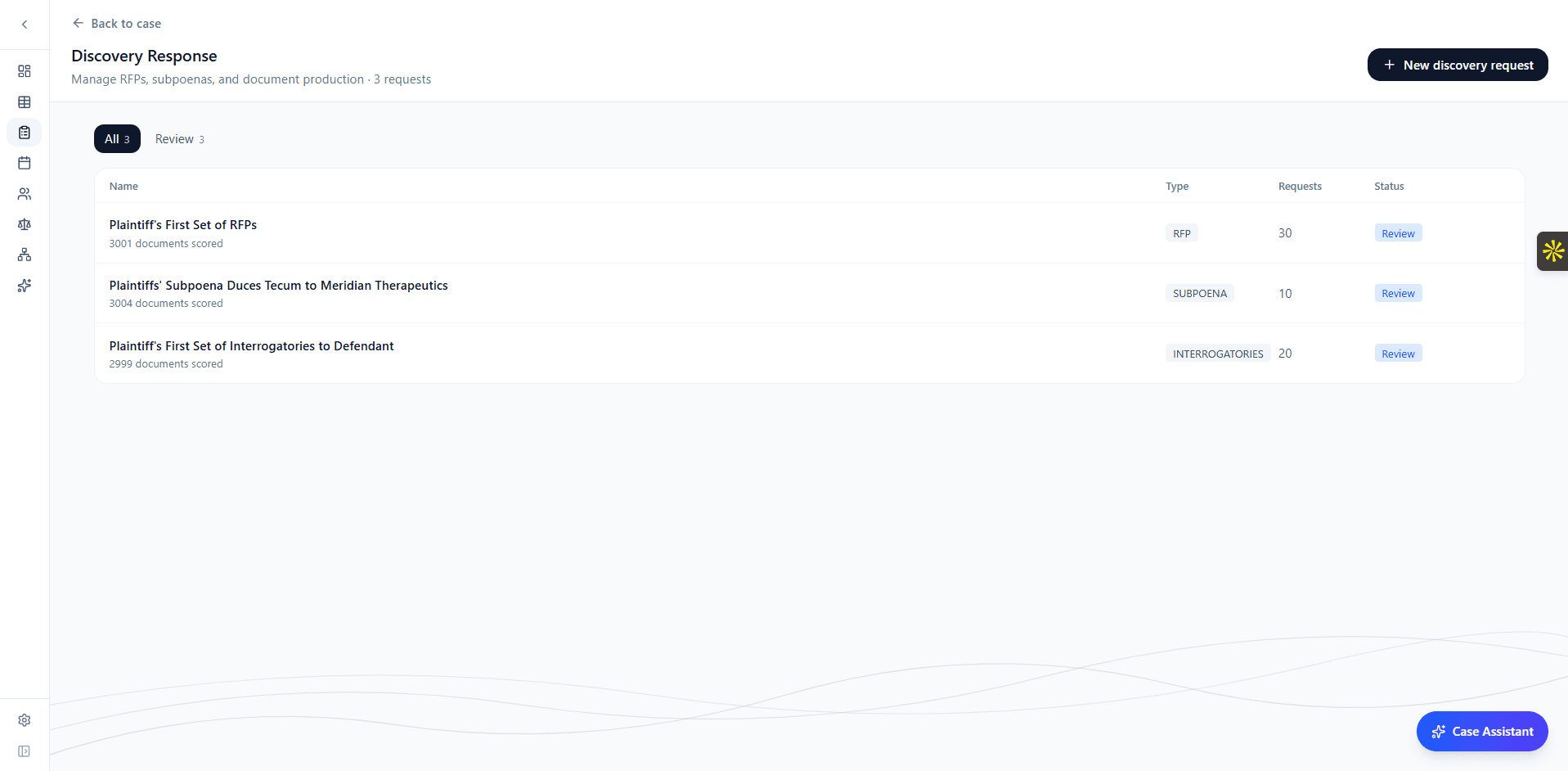
The workflow begins with a discovery request. Upload an RFP, subpoena, set of interrogatories, or RFAs, and the system reads the document, identifies its type, extracts every individual request item with its original numbering, identifies the requesting party, and categorizes each item by subject matter (emails, contracts, financial records, communications, etc.).
The extraction uses structured output parsing to understand the legal format of the document and separate individual requests even when numbering is inconsistent or requests are nested. Within seconds, you have a fully structured set of request items ready for review and editing.
You can review and edit the extracted items, adjust categories, add notes, and set relevance thresholds before proceeding. The system is designed so the attorney is always in control of how the requests are framed before scoring begins.
Stage 2: Per-Request Semantic Scoring
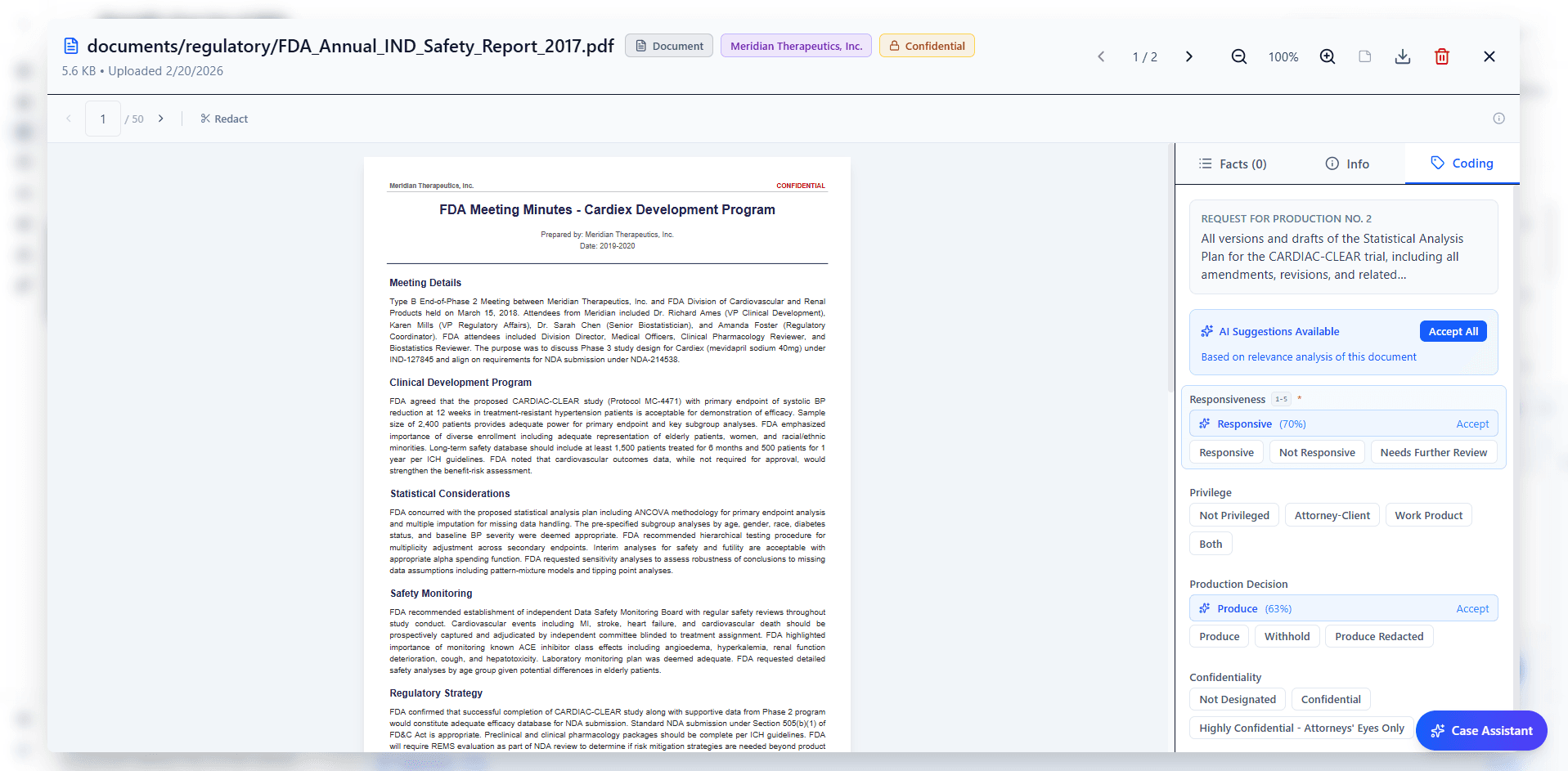
This is the core architectural difference from TAR. Rather than training a single binary classifier for the entire matter, Lumios scores every document against every individual request item, independently. A single document might score 92 against Request 5 ("all communications regarding the merger"), 15 against Request 12 ("financial projections for Q3 2025"), and 0 against Request 20 ("employment disputes"). Each score comes with a written explanation of the reasoning: not just a confidence number, but a natural language assessment of why the document is or is not responsive to that specific request.
The scoring operates zero-shot. The LLM reads the full text of the request and the full text of the document and evaluates relevance directly, without any training data from the current case. This eliminates the seed set coding phase entirely (typically 8-20 hours of senior attorney time in a TAR workflow) and removes a known limitation where the training attorney's interpretation of relevance permanently shapes the classifier's behavior.
Each assessment produces a relevance score from 0-100 and a natural language explanation. Documents are automatically bucketed by relevance:
- High (80-100) - Directly responsive to the request.
- Medium (40-79) - Moderately relevant. Warrants review but may not be responsive.
- Low (1-39) - Weak or tangential relevance.
- None (0) - No meaningful connection to the request.
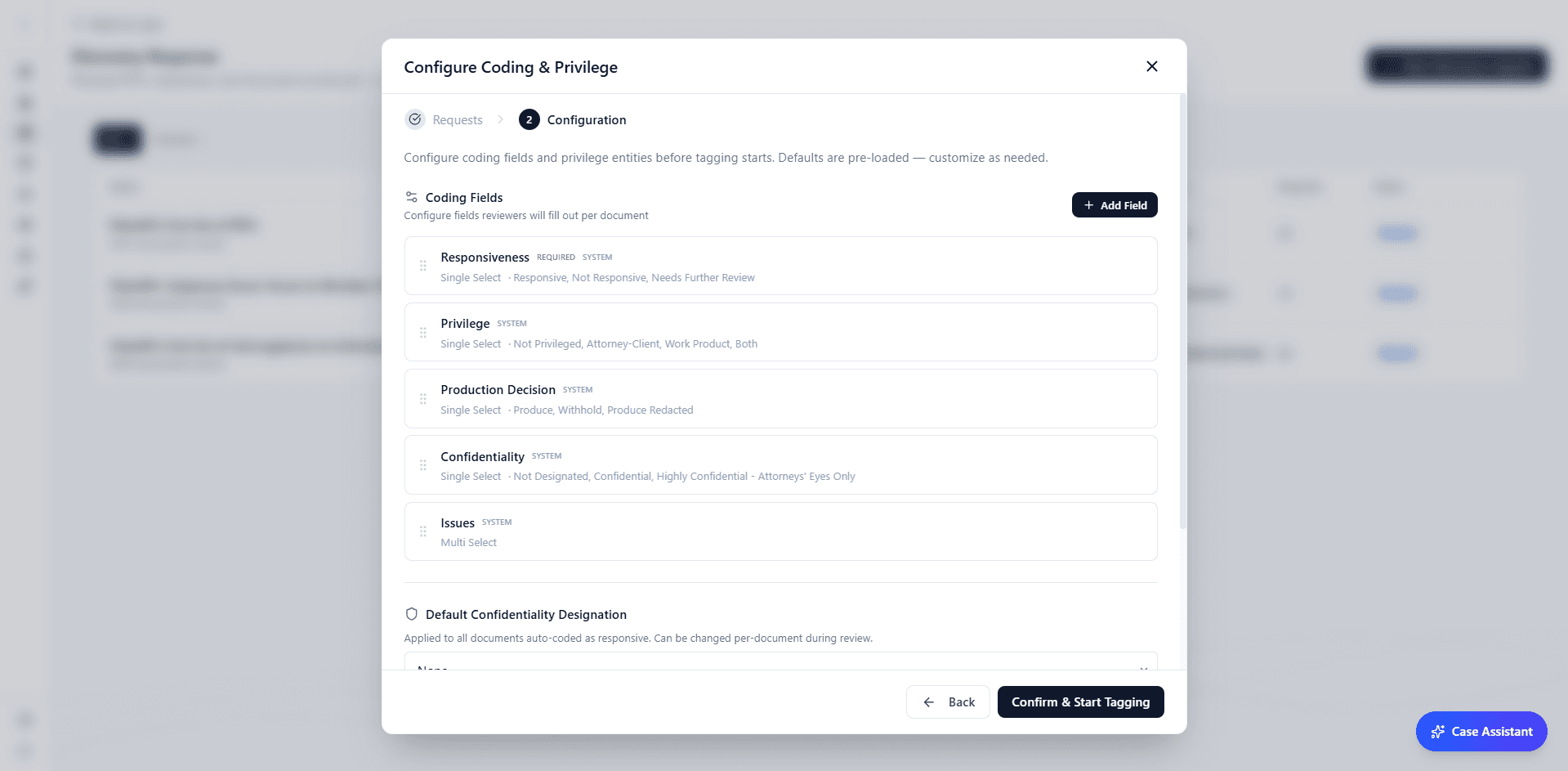
The system then applies conservative auto-coding. The thresholds are deliberately asymmetric: scores of 80 and above are auto-coded as responsive, but only a score of exactly 0 is auto-coded as not responsive. Everything in between (1-79) is left uncoded for human review. This conservatism is intentional: LLM relevance scores do not follow a normal distribution, and a score of 20 still means the model identified some connection to the request. Only a score of zero represents sufficient confidence for automatic exclusion.
Every auto-coded decision is recorded in the audit trail with the identity of the system, the score, the reasoning, and the model version. The attorney can review any auto-coded decision and override it. Nothing is hidden or irreversible.
Stage 3: Attorney Review
By the time an attorney opens a document, the AI has already provided an initial assessment. Every document comes pre-loaded with suggested coding values: responsiveness, privilege status, confidentiality designation, and production decision, each with a confidence score. The reviewer's task shifts from analyzing each document cold to evaluating the AI's assessment and applying judgment where it matters.
The coding panel is fully configurable. You define your own fields (any combination of multi-choice, text, date, or boolean) and the AI generates suggestions for each one. Every field maps to keyboard shortcuts. When the AI provides a consistent baseline, reviewers are calibrated against it rather than relying purely on individual judgment - which helps address the consistency problem that Roitblat et al. documented.
Batch operations allow you to confirm or override multiple documents at once. For quality control, the spot-check workflow pulls statistically significant random samples and lets you validate with keyboard shortcuts. Sample sizes are calculated using the hypergeometric distribution with finite population correction, and the system determines the required sample automatically based on your desired confidence level.
Privilege is the highest-risk area of any review. An inadvertently produced privileged document can waive privilege permanently. Lumios implements three independent layers of privilege protection. First, the AI evaluates each document during scoring for indicators of attorney-client communications and work product, considering sender, recipient, and content. Second, an entity-based scan checks every document against your list of known attorneys, firms, and in-house counsel. Third, and most importantly, privilege determinations are always made by an attorney. The AI flags potential privilege; it never resolves it. Every flagged document defaults to Withhold and is routed to a reviewer who must affirmatively classify it before it can be included in any production.
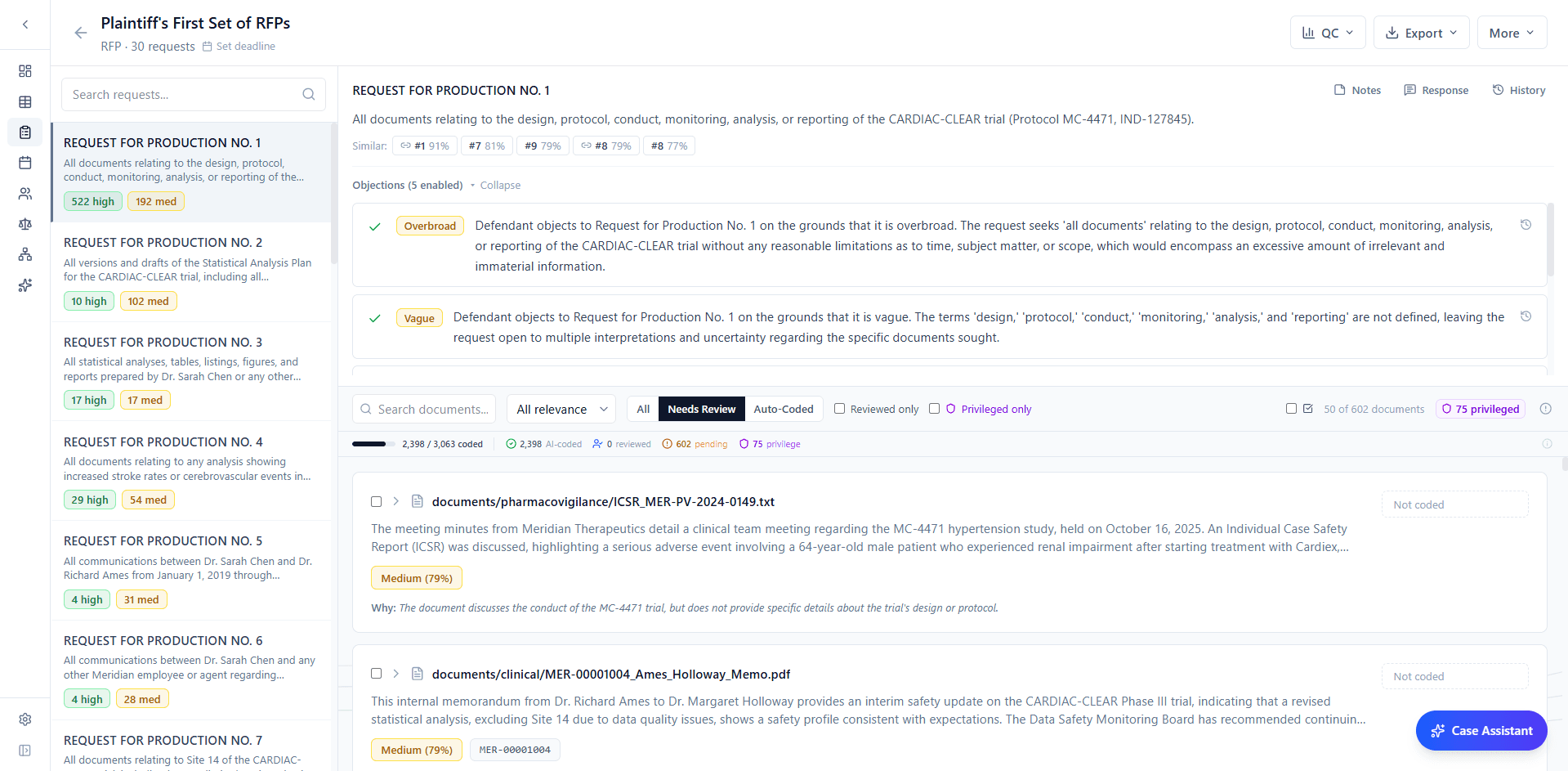
Discovery requests frequently overlap. In a 30-request set, it is common for 5-10 requests to address substantially similar subject matter. The system identifies these overlaps through cross-request intelligence: if two requests share 90% or greater semantic similarity and a document is coded responsive for one, it is automatically coded for the other, with the audit trail noting the propagation source. For requests in the 70-89% similarity range, the system surfaces suggestions for the reviewer to accept or reject. This eliminates redundant review of the same document against nearly identical requests.
When a reviewer corrects an AI suggestion, the system does not just record the correction. It re-evaluates similar documents in the background. Correct a privilege call on one email thread, and the AI updates its assessment across related messages. The model improves as the attorney works, not after the review is complete.
Stage 4: Objections & Responses
For each request item, the AI generates candidate objections (overbroad, vague, unduly burdensome, privilege, relevance, compound, temporal scope, and others), each with a strength rating (strong, moderate, or weak). The objections are jurisdiction-aware and case-type-aware, drawing on the court, jurisdiction, and case metadata provided. The attorney enables, disables, or edits each objection.
Every request item is embedded and indexed using vector similarity search. When the attorney edits an objection or toggles one on or off, the system identifies semantically similar request items across the discovery set and surfaces the edit as a suggestion on those items. This reduces the redundant work of applying the same objection reasoning to overlapping requests. The attorney still approves each change, but the drafting is not repeated from scratch.
For substantive responses, the AI generates drafts using the actual responsive documents, enabled objections, and case context. RFP responses reference specific productions. Interrogatory answers cite relevant documents. RFA responses use the appropriate admit/deny format. Each draft is presented in a rich text editor where the attorney has full editorial control.
The system tracks how the attorney edits responses and incorporates those patterns when generating subsequent drafts. The more responses the attorney refines, the more closely the AI's initial drafts reflect their style and approach.
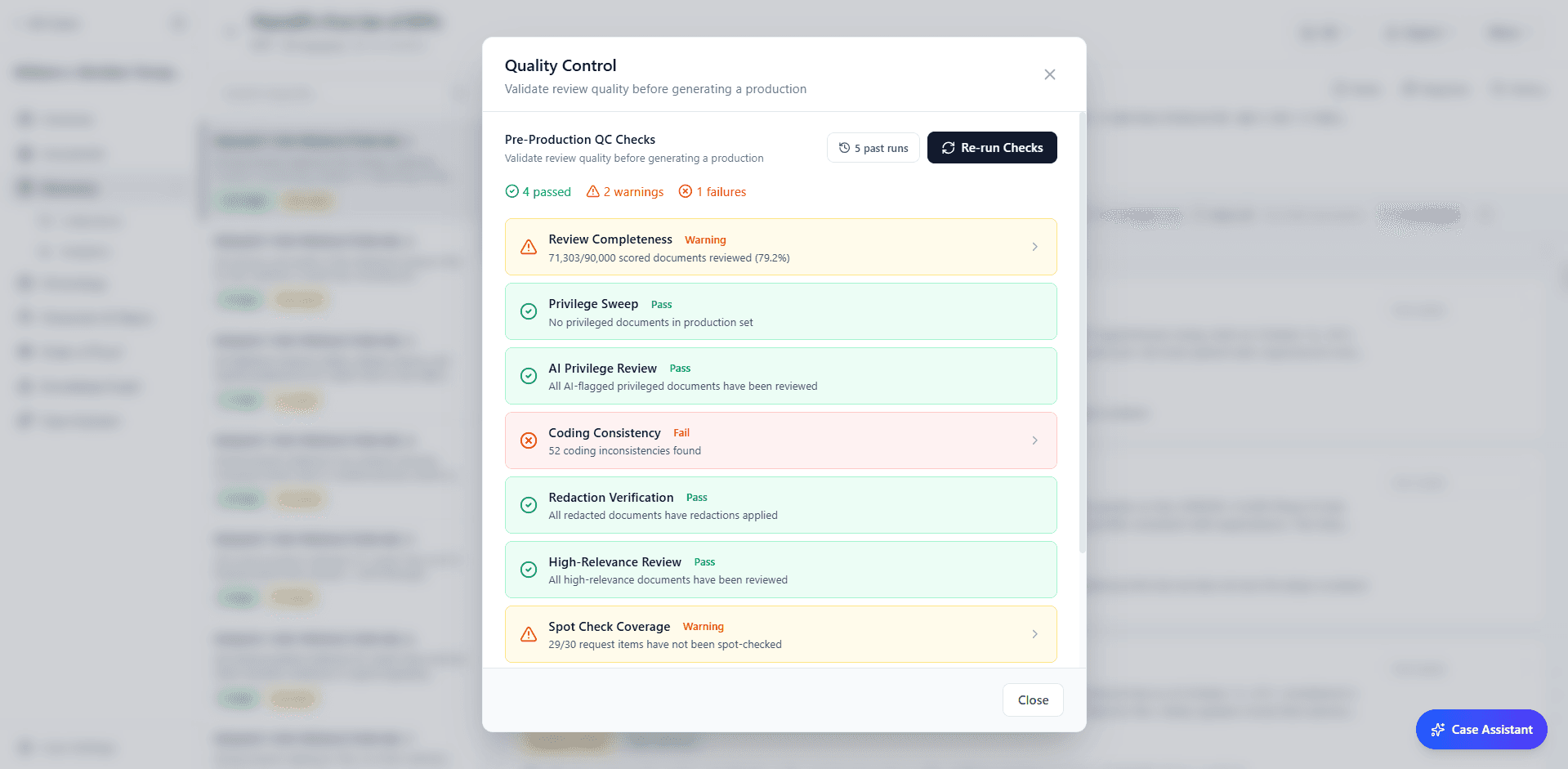
Stage 5: QC, Redaction & Production
Before anything leaves the platform, the QC dashboard runs automated pre-production validation. It checks review completeness, flags coding inconsistencies, performs privilege sweeps to catch missed privileged documents, verifies redactions, and validates high-relevance review coverage. Each check either passes or surfaces specific issues to resolve.
The visual redaction tool allows you to draw redactions directly on documents with click-and-drag markup. Assign a reason to each redaction (privilege, confidentiality, irrelevance), and the system tracks them in the privilege log automatically. Redactions are applied as overlays; the original document is never modified.
Before any production, the system prompts the reviewing attorney to confirm that a FRE 502(d) stipulation or order is in place, providing blanket protection against privilege waiver from inadvertent production. If none exists, the system displays a warning and logs the attorney's acknowledgment. As Judge Peck has observed, failing to obtain a 502(d) order when using technology-assisted review is "akin to malpractice."
The production runner handles Bates numbering, format conversion, endorsement text, privilege log generation, and DOCX/Excel export. Configure the production parameters, generate the package, and download a complete production ready for delivery.
Defensibility
Courts have recognized the legitimacy of computer-assisted document review through a progression of decisions. In Da Silva Moore v. Publicis Groupe (S.D.N.Y. 2012), Magistrate Judge Peck held that computer-assisted review is an acceptable way to search for relevant ESI, establishing key requirements: transparency of methodology, quality control measures, and validation through statistical sampling targeting recall of approximately 80%. In Rio Tinto PLC v. Vale S.A. (S.D.N.Y. 2015), Judge Peck declared TAR to be "black letter law." More recently, in EEOC v. Tesla, Inc. (N.D. Cal. 2024), Judge Corley's stipulated order formally contemplated generative AI in document review, establishing three requirements for its use: transparency, statistical validation, and party agreement.
The Lumios methodology is designed to meet and exceed these standards. Every action in the system is logged to an immutable audit trail: who made the decision (the system, a specific attorney, or a propagation from a similar item), when, what the AI suggested, what the reviewer chose, and why. The trail captures before/after values for every change and is fully exportable for methodology disclosure.
Elusion testing validates that the "Not Responsive" pool does not contain a significant number of responsive documents. Sample sizes are calculated using the hypergeometric distribution with finite population correction. For a population of 1,800 documents coded as not responsive, 95% confidence at a 5% margin of error requires reviewing 317 documents, not 1,800. The system calculates this automatically, tracks running elusion rates, and reports recall estimates with confidence intervals at both 95% and 99% levels.
Where TAR produces a confidence score, every Lumios scoring decision includes the natural language reasoning, the model version, the prompt version, and any reviewer overrides. This level of transparency is designed for the kind of methodology disclosure that courts are increasingly requiring for AI-assisted review.
The framing is important: this is AI-assisted human review. The AI scores, suggests, and drafts. The attorney confirms, overrides, and approves. The audit trail documents that the attorney was the decision-maker at every stage.
Why We Built This
The cost of discovery creates real consequences for access to justice. Clients with resources can afford comprehensive review processes. But for individuals and businesses represented by solo practitioners or small firms, the cost of responding to discovery can exceed what the underlying claim is worth. When clients are forced to settle not because of the merits but because they cannot afford the process, the system is not working as intended.
AI-assisted review with statistical validation can meaningfully change that calculus. By auto-coding high-confidence decisions and routing only uncertain documents to human reviewers, the billable time passed on to clients is focused on the subset of documents that genuinely require legal judgment, not on the repetitive pattern-matching work that consumes the majority of hours in a traditional review.
This is not AI replacing attorneys. It is AI handling the work that does not require legal expertise (the initial relevance assessment, the consistency checking, the first draft of boilerplate objections) so that attorneys can spend their time on the decisions that do. The attorney remains the decision-maker. The methodology is more consistent than manual review, more transparent than traditional TAR, and validated to courtroom standards.
The legal framework is emerging in support of these tools. The technology exists today. We believe the legal profession will be better for adopting it, and more importantly, so will the clients who bear the cost of discovery.
Want to see it for yourself?
We're running sandboxes on mock case data so your team can experience the full discovery workflow. Book a call and we'll have you set up in 20 minutes.
Book a DemoBest,
Dhruv & Arnav